Ready to achieve your goals and get more out of life? Join 50,000 ambitious professionals who are pursuing productivity, growing their career and creating financial freedom.
AI is not magic. It's just math.
|
One of the cardinal rules of investing is: If it’s too good to be true — it probably is. When it comes to AI, I don’t think it falls in the “too good to be true” category. Yet. But it’s damn good. And I use it all the time. Yet I don’t want to be blind and naive about its limitations. And while I want to understand what is happening under the hood — I have no appetite for the super technical details. Andrej Karpathy was on the founding team of OpenAI and has the most incredible video primer on How LLMs work. However, it’s 3 hours and 30 minutes long and I don’t think most people will put in the work. (Your loss.) But it inspired me to use Karpathy’s framework to explain to my smart (and non-technical) professionals what’s really happening when you engage with ChatGPT. Meet the Most Knowledgeable Person in the WorldThis is Aiepon (pronounced “AY-uh-pon”, who shares her namesake with OpenAI.)
Aiepon will go from a tiny child to the Most Knowledgeable Person in the World. It turns out that her learning journey will closely resemble how LLMs are built and trained for us to use. We’ll cover:
Phase 1: Pre-training and “The Sponge”From a young age, Aiepon has always been a sponge. A bookworm. An Internet Nerd. A voracious learner. And a perceptive observer of the world surrounding her.
Your favorite LLM works the same way. During the Pre-Training Phase, it ingests billions of documents from across the Internet, including:
Try it yourself:Visit huggingface.co for open source data sets that are used to train the models.IMDB Large Movie Review Dataset with 25,000 highly polar movie reviews for training, and 25,000 for testing.
This data set is massive and must then be cleaned up and distilled so that the model can then be trained. From Words to Tokens: Breaking Language into Smaller ChunksBut Aiepon doesn’t just memorize entire textbooks or academic papers. She breaks them into digestible chapters, sections, flash cards and cheat sheets so that the information becomes easier to process, access and retain.
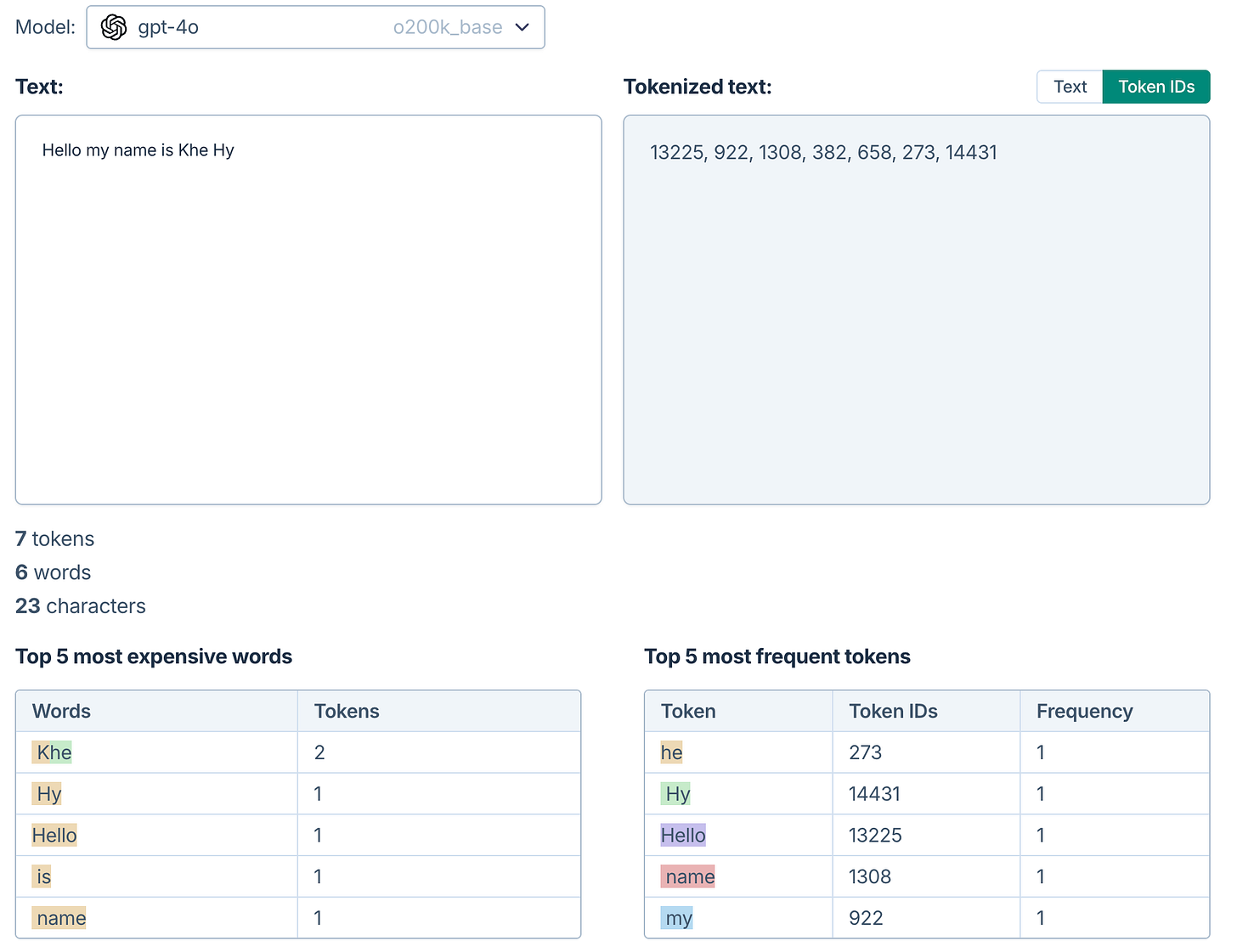
LLMs have a similar process called tokenization. ChatGPT doesn't process full sentences or paragraphs at once. It breaks language down into tokens – smaller units that might be words, parts of words, or even punctuation. For example: “ChatGPT is amazing!” might be broken into something like: "Chat", "GPT", " is", " amazing", "!" This tokenization is crucial for a few reasons:
There are free websites that let you try out tokenization (Like the OpenAI Tokenizer):
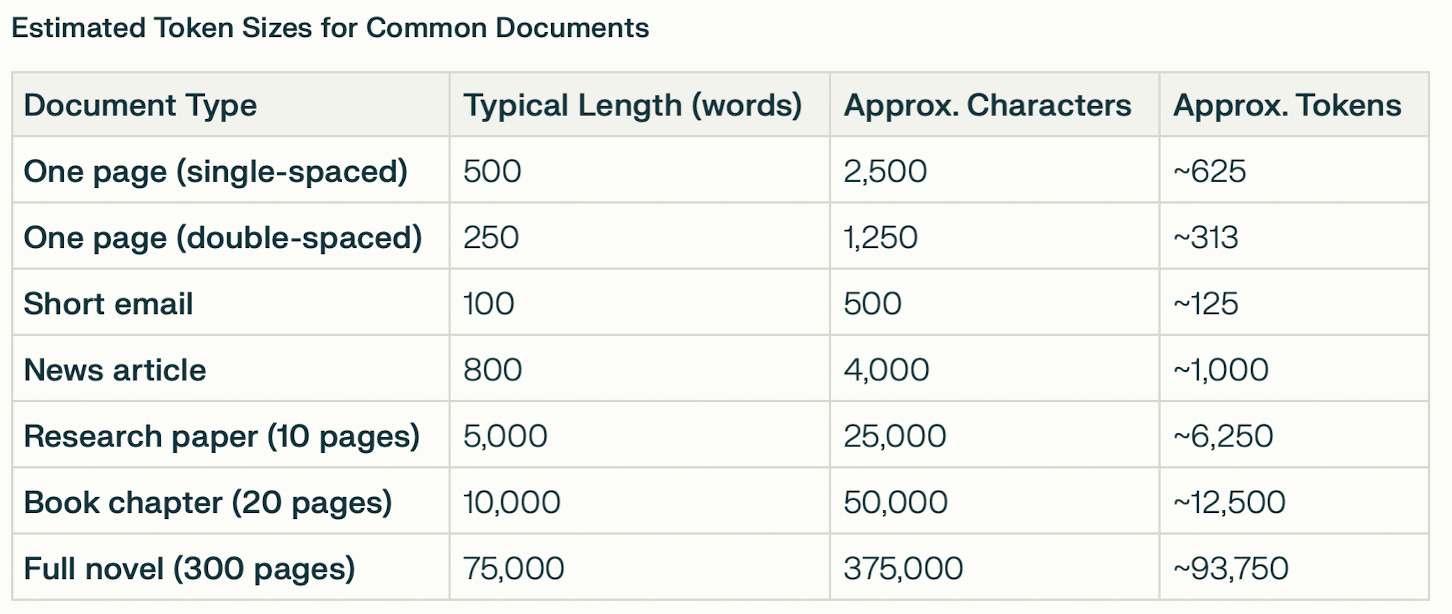
According to OpenAI: A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words). What’s interesting is that “KHE” (i.e. an uncommon word) is the only sequence that’s represented by two tokens. You’ll often hear about tokens in the context of “context windows” — the amount of information that can go into a prompt. Here’s a quick table of tokens sizes:
(And for context, ChatGPT 4o has a context window of 128,000 tokens — so one novel and 5 research papers.) Neural Networks: The Architecture of the BrainIt’s not enough for Aiepon to have all this information in her brain. She needs a way of connecting it all in a cohesive manner. She hunts for patterns, spotting how words and sentences fit together. For example, she notices that the phrase “I love” is often followed by something nice like “dogs” or “ice cream.” She quizzes herself, by covering portions of text and guessing what comes next. She realizes that a phrase like “The cat and the ____” is usually followed by the word “hat.” And that “Donald” is usually followed by “J. Trump” or “Duck.” With repetition, her guesses get better and better. And finally, she puts together a mental map of all the knowledge — recognizing that “cat” and “dog” are both pets and that “sadness” and “anger” are both negative emotions.
At the heart of an LLM is a neural network – a mathematical structure loosely inspired by our brains. Picture it as a vast web of interconnected nodes (or "neurons") organized in layers. Each neuron is like a tiny decision-maker that takes some input, applies a weight (i.e. a probability), and passes its output to the next layer. Modern AI systems have billions of these adjustable "dials" (called parameters). During training, the system tweaks these dials to get better at predicting text. This approach works particularly well with sequential data (like text) since it focuses on the relationship between words, no matter how far apart they are in a sentence. Here are a few examples of what’s happening during this step:
The neural network phase of pre-training is massive. ChatGPT-4 reportedly cost over $100 million to train over a 3 month period. The energy used to train these models can power hundreds of homes for a year. Be careful of "knowledge cutoff" dates
The world’s best autocompleteAt this point, Aiepon has essentially become the world's best autocomplete. She can predict with uncanny accuracy what words should come next in any sequence.
But while she's brilliant at completing sentences, she still lacks the judgment to determine what's actually helpful. This brings us to the second phase: Learning not just what she could say, but what she should say. Phase 2: Supervised Fine-Tuning and “The Apprentice”Despite being extremely well read, Aiepon begins to experience the limitation of raw knowledge. Yes, she “knows” all the source material — but she rambles, goes off topic and sometimes makes things up. In Phase 2, Supervised Fine-Tuning (aka SFT) the LLM learns to provide useful outputs with the help of human feedback and training.
Supervised fine-tuning, explainedSFT is the bridge between a raw, pre-trained model and one that can actually follow instructions. And guess who plays a critical role in this phase? Humans. Ah yes, the irony. SFT involves human experts creating thousands of “sample pairings” of prompts + ideal response to guide the model into producing more useful and coherent outputs. Meet the human annotatorsThese annotators are often contractors with specific domain expertise and they write out example prompts, such as:
A typical LLM would inject between 10,000 and 100,000 pairings (once again, all created by humans) — a tiny fraction of the size of the pre-training data. An example prompt + ideal response pairing: “Can you help me plan a weekend trip to a nearby city?”Response: “I’d love to help! Could you share where you’re located or what kind of vibe you’re looking for—like a cozy small town, a bustling city, or somewhere with great hiking? That’ll help me suggest the perfect spot.”Behind the scenes:
These prompts are then paired with a specific (human-generated) response and the goal is to prioritize clarity, helpfulness and formatting in the responses. Compared to the pre-training phase, SFT is surprisingly straightforward. The model continues to “autocomplete” (i.e. predict the next token) but now it has an additional “instruction following” lens. This phase is significantly cheaper (both in time and GPU usage) and delivers substantial improvements with just a fraction of the compute power. The key challenge isn’t the technical implementation — it’s getting the best data-set covering the widest range of human interactions. A quick sidebar: Reinforcement LearningAiepon is about to throw us a little curve ball. Stand up comedy. She’s going to try out a bunch of jokes in small clubs to see how the audience responds. After each set, she’ll review the feedback and then only perform the jokes that performed better.
This mirrors the next sub-step of SFT, Reinforcement Learning From Human Feedback (aka RLHF). Here’s how the process works:
Reinforcement Learning is an automated version of trial and error. It starts with the human evaluators, but over time the LLM takes over to learn what humans value most in a conversation. What made DeepSeek so unique?Remember how this Chinese AI startup came out of nowhere and made massive strides against its more established US competitors?
Phase 3: Inference and “The Wise Sage”In our last phase, Aiepon is now ready to set sail and share her knowledge in the real world.
In her journey from sponge to wise sage she no longer regurgitates memorized answers. Now, she creatively crafts new responses by assessing the context of a particular situation. For LLMs, this final process is called Inference. It’s the moment of truth where the model interacts with users in real time— generating responses based on its pre-trained knowledge and fine-tuned skills. The input stage and context windowAs you type your prompt, the LLM works to assess what pieces of information it needs to act about. The context window means that model can only “see” a certain amount of text. The model is constantly managing this window, deciding what to keep and what to discard. The limitations of the context window
The processing stage and token predictionArmed with the context window, the model then rapidly processes your prompt token-by-token to assess the next token (via a process called attention mechanism). It then proceeds to generate the output iteratively, predicting one token at a time. The model doesn’t just pick one answer — it creates a probability distribution, which is why the same prompt often yields a different response. The generation stageFinally, words are generated one at a time with a feedback loop. As it generates a word, it improves the probability of the next word. This happens in milliseconds, adding to the computational demands of the entire process. While still significantly less than the Pre-Training phase, a single complex query can use about the same electricity as charging your smartphone! Tying it all togetherAiepon is all grown up and is now a wise sage… your wise sage.
But that doesn’t make her perfect. And it’s important to remember that while AI acts like magic, it’s just a bunch of math. It’s pattern-matching on an incomprehensible scale. But it’s not sentient, nor does it have a consciousness. I hope this tutorial gives you a more robust understanding of the architecture of an LLM. Understanding this helps you make better decisions about AI’s use cases and limitations. Since you’ve made it this far, it’s clear that you want to become more AI adaptive and resilient. I encourage you to ponder these 5 questions:
See you next week! Khe PS Did a friend send this to you? Sign up for our free newsletter. |








RadReads by Khe Hy
Ready to achieve your goals and get more out of life? Join 50,000 ambitious professionals who are pursuing productivity, growing their career and creating financial freedom.
Hey Reader, We made it back stateside after an incredible trip to Japan. Lisa and I even managed to squeeze in an Omakase date night in Tokyo. Here's one of our last pics from a swanky rooftop bar. I'm starting a small mastermind for finance professionals looking to master AI. Learn more about the program below ⤵️ Apply for the Mastermind → Here are this week's top reads: // one What happens when you leave your career (and identity) behind 20 minutes | Andy Johns Substack Occasionally, I...
Hey Reader, Greetings from Japan. We're fully immersed in yakitori, micro pig cafes, Zen gardens and 7-11 pork buns. It's awesome. I've also been writing two posts a week on AI developments over at Future-Proof Your Career with AI. It's totally free, check it out (it's a separate newsletter). Sign up for free → Here are this week's top reads: // one You should be setting rejection goals 10 minutes | Vox What would life look like if we didn’t take rejection so damn personally. Our fear of...
Hey Reader, Greetings from the Shinkasen on our way to Kyoto. The trip’s off to a great start. I even bit the bullet on Premium Economy, no regrets. I wanted to share the most impactful online course I’ve ever taken. This January, I was in a rut, looking for a new challenge. I randomly took Nat Eliason’s course Build your own Apps with AI and got hooked on coding. I built some amazing things like my new website and a buy vs. rent calculator). But the biggest unlock was a completely new...